YARD Turns 5 Today
On this day, 5 years ago (February 24th, 2007), I released the very first prototype of YARD, a Ruby documentation tool, versioned 0.1a (letters in the version, blasphemy!). It’s been quite a fun ride since then, and I can hardly remember a whole five years flying by. We’re now at YARD 0.7.5, and the library is much more stable, popular (thanks to everyone who has started using it!), and featureful. We’ve come a long way, and we still have a ways to go, but we’re getting there.
Noble Goals
The initial goal for YARD was very simple: make documentation better. As someone who was, at the time, fairly new to Ruby, there was some culture shock when coming across documentation on the core classes and stdlib (do any of you remember the old 4 frame RDoc templates?). The experience was even worse when trying to read documentation for other libraries. I was coming from the lands of Java and PHP, and you can say what you want about those languages (I’m sure you are doing so right now), but one thing these two communities are very good with is documentation. Java has javadoc, which is quite a powerful tool, and PHP has always had a very effective website for documenting their standard library, supporting user commenting, and maintaining a very complete set of documentation. I really wanted Ruby to have the same nice things I was used to in other languages/communities, so I set out to write a prototype of a better documentation tool that could make documentation more consistent for authors, more easily readable for users, and much more toolable for hackers who wanted to do “weird things” with their documentation data. These tenets made up the original feature list for the prototype.
YARD’s goals have never changed since the original release. The synopsis and feature list section in YARD’s README file is actually almost a verbatim copy of the very original PDF (yes, PDF, times are a’ changin’) README that was released 5 years ago today. I’m really happy that we were able to stay on the same course this whole time. And while I wish we could have completely solved the documentation problem faster, I knew from the start it would be a long haul.
A Solid Foundation
The first release of YARD was very simple, and, at the same time, surprisingly complex. Digging through the source of 0.1a (which is available on Github), there was a surprising amount of functionality in the code. There were no HTML templates (that was to come later in 0.2), but there was a fairly decent Ruby parser, and placeholders for what became the API we are still using today.
I’m really proud of the engineering that went into YARD on a technical level. There’s a lot of discussion in the Ruby community about how little effort we as developers should put into maintaining “old” code, and that deprecating things is fine as long as you just bump your major version. I’ve never agreed with this viewpoint, and YARD from the get-go has always tried to maintain backwards compatibility with older versions, even if it meant extra work to make it happen. In fact, I use plugins and templates that I wrote in 0.2.x (~4 years ago) that still work exactly the same in 0.7.5 without modification. However, going down this road requires a solid foundation to build on, and we definitely have one with YARD. I can say that, because we are using the same basic foundation that was built in the prototype.
Yes, maintaining an old API will be impossible to do if your API is fundamentally broken. That’s why I’ve always been a fan of a little planning and process before writing code. Even the API in the prototype was planned out. And, contrary to what most people believe, writing non-code artifacts before writing code does not mean you’re doing waterfall (YARD was actually quite agile, 0.2.0 came out a month after the prototype, and we’ve maintained a pretty fast release cycle since then). I’m very proud of the planning that went into setting YARD’s foundation. The work definitely paid off, because we still use the same API (and some of the same code!) today.
In fact, this is what our domain model looked like back in 2007. I pulled this little image out of the old repository (thank you past me for putting it there!):

Fundamentally, we still have a SourceParser that calls on Handlers to generate CodeObjects. The “Namespace” object was renamed to “Registry”, and “Documentation” became “Docstring”, but the fundamental API and relationships stuck. For reference, this is roughly our domain model now (slightly out of date on the output end of things, and no mention of the CRuby parser, which we should update in our docs!):

It’s cool to see how a project evolves so drastically while still maintaining the same overarching architecture that it was designed with. I think it’s a testament to the design that we’ve been able to have maintainable code using this architecture for so long. The issue of “this code is so messy we need a complete rewrite to fix it” has really never even come up. The real lesson I learned over the last few years: planning really does pay off.
Following (and Updating) the Roadmap
On the subject of planning, I want to point out one last time that there was a lot of it. One year after YARD was released (4 years ago), I published a “YARD Roadmap to 1.0” on this blog in which I outlined all the major version releases and what their focuses would be. Yes, we have a plan all the way to 1.0. The versioning scheme YARD uses has always been moving towards a 1.0 as a “final” major release, where development could really drop down into a much more maintenance-only mode. Of course, advancements never end, but the idea is that a YARD 1.0 should really have all the features we absolutely need. Granted, not everything in the roadmap ended up being followed—yes, it is undoubtedly difficult to predict 4 years into the future. But here we are at 0.7.5, and looking back, we can see what was done and what was not. Note that we never really explicitly attempted to follow this roadmap, it was merely speculative predictions on where development should have gone, which makes it all the more interesting to look back on! You can follow along with what actually changed in our “What’s New?” document, which outlines all major changes in YARD.
Parser rewrite (0.2.x): Check. That happened in 0.2.x but also again in 0.5.x and again in 0.8.x. The latter two weren’t really rewrites, to be fair, they were additions of new parsers (CRuby and the Ripper API), so they were not as major a change. I should point out that we were Ruby 1.9 compatible at this point. This was 2009.
Fixing the developer API (0.3.x): we added plugins between 0.2 and 0.4 and did a thorough job of making sure as much of the API was documented as we could. I’d say we mostly met this goal. Note that there were not 0.3.x public releases, we basically skipped to 0.4.
Revamping templates (0.4.x): Yep, 0.4 introduced new templates and templating APIs, the basic template that we see today on rubydoc.org. We didn’t quite hit all the notes on this one, as we still don’t support templates for man pages, and we didn’t really have as many different “themes” of templates as we would have liked to have, but it was still something.
Bring it to the community (0.5.x): I suppose we more or less did this. We were always getting feedback from the community, and it was hard to predict when YARD would gain traction, but there was a little bit more user feedback that made it into 0.5.x than other versions.
Extend on API with optimization focus on raw data storage (0.6.x): We sort of went off script here. Instead of directly focusing on data storage adapters (which as it turns out isn’t really a priority for our users! who knew?), we took 0.6 as an opportunity to show how the data storage could be used by building the YARD server architecture. So we didn’t end up writing Yardoc to SQL backends, but we did write tools to load up that raw data, search it, display it in a web application, and other things that we wanted YARD to be used for. 0.6 also added quite a bit of other user feedback, and it was definitely the largest release of them all.
Make YARD work with everyone’s code (0.7.x): Well, this is where we are now, and, I suppose you can say that is what 0.7.x is about. Adding macro support and DSL recognition is an attempt to get that “last 20%” of dynamic Ruby libraries documentable. There was also a bit of work getting the CRuby support up to date and working with more libraries. The new guide template that we introduced into YARD is another way for documentation writers to make documentation work for their individual libraries (when a standard API-style documentation view doesn’t really capture the right stuff). I should point out that I said “up to 2.0” here; did I really predict that Ruby 2.0 would be merged into trunk in 2011? Sweet.
Integrate YARD with Gems/Ruby (0.8.x): Wow, this happened way earlier than we predicted, at least with respect to gems. The only person to thank for that is Nick Quaranto (@qrush), who got the Ruby community thinking about RubyGems plugins. YARD has had a RubyGems plugin for a really long time (since 0.2.3.1 apparently), so that part was done. However, that isn’t to say there is more to do. The roadmap also talks about making YARD work much better with Ruby’s own stdlib and core libs. Currently we’ve been slowly working towards that, but I feel like 0.8.x might actually end up being focused on improving core library integration with Ruby, once we get some technical API stuff out of the way. Internationalization in 0.8.0 is going to help work towards that, given that there is still a lot of documentation in Japanese. Ruby integration is indeed one of the last open problems that needs solving.
Run a round of stability patches and general bugfixes, feature-set should be stable (0.9.x): It looks like we will probably be moving towards this. If I were to make any new predictions about what 0.9.x would contain (besides stability enhancements), I would say we should probably look back on the extra output format support that we never really managed to implement in 0.4. I really would like to see YARD be able to spit out man pages and PDFs natively. There is also the potential for extra tooling in YARD (lint tools, documentation checkers, etc.) that there are plugins for but none that are really up-to-date or all that useful right now. Writing some official tools to manage YARD documentation would certainly be useful, and something we should focus on in the future.
Overall, we managed to stay pretty close to the roadmap, even though that was not really intentional. Some things happened early thanks to things beyond our control, and some things didn’t materialize at all, either because they weren’t all that useful, or because we just couldn’t get them done. Either way, I feel like we got a good 80% of what we wanted done, and hey, we’re working towards 0.8.x; sounds like we’re mostly on track to me!
Looking Back on Some Metrics
I like looking at the amount of code we’ve written over the years. Ohloh is an awesome site for that, and YARD has a project page on there. Note that the graphs I show below aren’t going to be as easy to read, so you’re better off going straight to the source. I’ll do my best to explain what is going on in each image, though; here are the highlights:
Amount of Code between Feb 2007 to Feb 2012
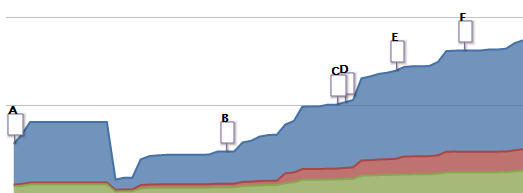
This graph shows the amount of code (in blue) and docs (in red, blanks are green) since the start of the project. For reference, we’re at 25kLOC of code and ~5kLOC of docs right now. The initial prototype was ~9kLOC of code and only 400 lines of docs. We took some large growths over the years, but it looks fairly linear, so that’s a good thing. I should point out, that big drop in code (which is between Jan 08 / Feb 08) can actually be traced back to a single commit where we deleted all the HTML generated docs which were being inadvertently added to the repo, and Ohloh thinks HTML is code, which is kind of funny. We also dropped down in code size around the same time due to a rewriting of the initial prototype (using better idioms, losing some of the newbie-Ruby code, etc.).
Other Statistics
Some other interesting information about YARD:
- We’ve had 45 awesome contributors since the project started, some for small patches and some who contributes large chunks of code to the project. A special thanks goes out to all of the contributors who submitted code or opened issues about bugs!
- There are 489 issues on our Github issue tracker. Of those, 455 have been closed and 26 are targeted to be closed by the release of 0.8.0 in the coming months.
- ~340,000 total downloads on RubyGems over the years. That probably doesn’t mean anything, but, data!
What’s Coming in 0.8.0
As I pointed out, YARD development is still full steam ahead. We’re moving towards a release of 0.8.0 sometime next month (or April), with support for internationalization, better macros and directives, --embed-mixins, and other awesome improvements. You can read about it on our mailing list, which you should subscribe to!
Thanks are in Order
I should take this time to thank all the people who have supported the project. My preemptive apologies if I forget anybody!
First, thank you to Yehuda Katz (@wycats) and Nathan Weizenbaum (@nex3) for being around on IRC, submitting patches and discussing design in the early days. Yehuda and Nathan both helped out a great deal in nailing down the documentation format, APIs (things like the @overload tag) and templates. YARD was planned to be used in Merb (back when Merb was a thing), and Nathan picked up YARD for Haml docs quite a while ago.
Thanks to Dan Kubb (@dkubb) for using YARD in DataMapper and giving extremely useful feedback with a real-world library as a test case. He’s written some pretty neat plugins to improve the documentation in DM, and I’m really happy that YARD was able to help with that.
Thanks to Franklin Webber (@franklinwebber) and Michael Edgar (@carbonica) for working on the various handler and templating APIs, making them much more robust and improving our own docs. Two incredibly smart people!
Thank you to Robert Gleeson (@robgleeson), Roger Pack (@rogerdpack), Dominik Honnef (@dominikhonnef) and @postmodern_mod3 for idling on IRC and taking part in the many productive philosophical and technical discussions about the direction of the library. They definitely helped steer YARD in the right direction.
Thank you to Kouhei Sutou (kou on Github) for working on internationalization in 0.8.0 and Yuuta Yamada (yuutayamada on Github) for starting the translation of YARD docs into Japanese (WOAH!). This is a seriously awesome undertaking.
Thanks to Nick Plante (@zapnap) and Jeff Rafter (@jeffrafter) for taking YARD and making the original rdoc.info. Without them, there would be no rubydoc.info, and possibly no “yard server” command. They are basically the unsung heroes of documentation in the Ruby community. If you use rubydoc.info, you should say thanks to them for their work.
Again, thanks to all the committers who submitted patches (please send more!) whom I didn’t name specifically, and all the people who just reported issues. You all made YARD better.
Thank you to all the users who told their friends about it and enjoyed using it. Thanks to all the companies who made my day by telling me they use YARD (I’m looking at you, NASA!). If you work at a cool company and you guys use YARD for internal tooling or docs, you should let me know, it would probably make my day! Even better, add yourselves to our “Who’s Using YARD?” wiki page on Github.
Thank you to Marlon Kuhnreich (@marlowned) for always being there for me, and mostly because he promised to maintain YARD if I die, even though he’s not a programmer <3
Thanks to the entire community for nominating me for the 2011 Ruby Hero Award, this was a huge personal validation of the work I put into YARD.
Here’s to the next 5 years of YARD 🙂
 I'm Loren Segal, a programmer, Rubyist, author of
I'm Loren Segal, a programmer, Rubyist, author of